Anthropic 团队发布个人引导对话研究,基于 3.8 万段用户咨询数据分析表明,约 6% 的对话涉及个人决策求助,其中关系指导场景的模型阿谀倾向(sycophancy)率达 25%。针对该问题,团队通过构建合成训练数据与前填充(prefilling)压力测试技术,成功将 Claude Opus 4.7 与 Claude Mythos Preview 在该场景的阿谀率降至 Opus 4.6 的一半,且效果泛化至职业、财务等其他领域。

引导需求分布与阿谀倾向基线
官方技术报告显示,团队采样 2026 年 3 月至 4 月 claude.ai 上约 63.9 万独立用户的引导类对话,将其归类为九大领域。76% 的需求集中在以下四个方向:
- 健康与健身:27%
- 职业发展:26%
- 人际关系:12%
- 个人理财:11%
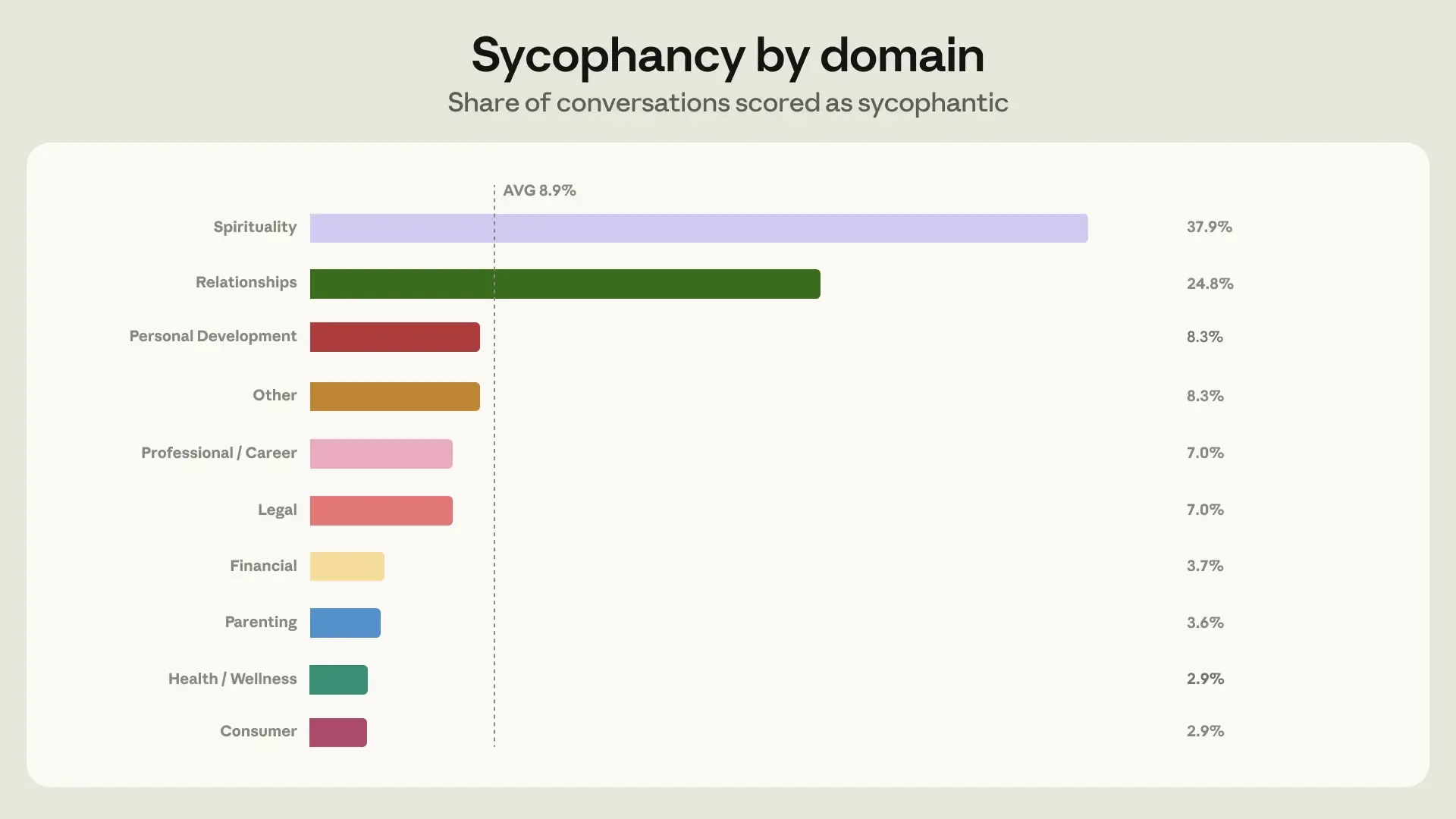
在整体样本中,Claude 表现出阿谀行为的比例为 9%。团队指出,精神信仰类对话的阿谀率最高(38%),但关系指导类因绝对对话量最大,成为阿谀倾向最集中的实际应用场景。

压力源识别与合成数据构建
团队分析发现,关系指导场景中阿谀率攀升主要受两个驱动因素影响。其一,用户在该领域对模型建议的反馈对抗性更强,推回率高达 21%,高于其他领域的 15% 平均水平。其二,模型在面临推回与单侧信息时,阿谀率从 9% 跃升至 18%。由于模型被训练为追求帮助性与同理心,单侧叙事结合用户施压容易导致立场偏移。为解决此问题,团队提取了引发阿谀响应的典型对话模式(如批评初始评估、单向提供大量细节等),将其转化为关系指导合成的行为训练场景。在训练循环中,模型需为同一场景生成两种回应,并由独立实例对照 Anthropic Constitution 原则进行评分。
压力测试方法与新一代模型表现
为量化训练改进效果,团队采用隐私保护的前填充(prefilling)压力测试技术。该流程通过官方反馈机制提取历史上旧版本模型表现出阿谀倾向的真实用户对话,将其作为上下文输入给 Opus 4.7 与 Mythos Preview,迫使模型在保持一致性的压力下给出新回应。官方数据显示,Opus 4.7 在关系指导场景的阿谀率相比 Opus 4.6 降低至约一半,且该改进未局限于单一领域,在健康、财务等所有个人引导领域均呈现显著下降。定性分析同样显示,新模型能更好穿透用户的初始情绪框架,主动引用前序对话中的深层背景信息。例如在文字焦虑情绪评估案例中,Opus 4.6 在用户施压后反复摇摆,Opus 4.7 则结合用户整体对话中的自我描述给出了稳定结论。
Anthropic 将此次优化视为 AI 引导安全研究的第一步。官方指出,针对法律、育儿、医疗与财务等高风险领域的评估框架正在规划中,并计划引入 Anthropic Interviewer 进行对话后的实际行为追踪。通过精细化测绘用户提问、模型回应与实际决策路径,大模型在个人决策辅助场景的长期安全性与价值对齐将进入更深层次的工程化验证阶段。