2026 年 4 月,人工智能标准与创新中心(CAISI)完成对开源大模型 DeepSeek V4 Pro 的第三方独立评测。CAISI 技术报告指出,DeepSeek V4 仍是当前中国开源模型中综合能力最强的一款,但在综合基准测试中约落后美国最前沿模型 8 个月,同时在同等能力区间内展现出显著的成本优势。
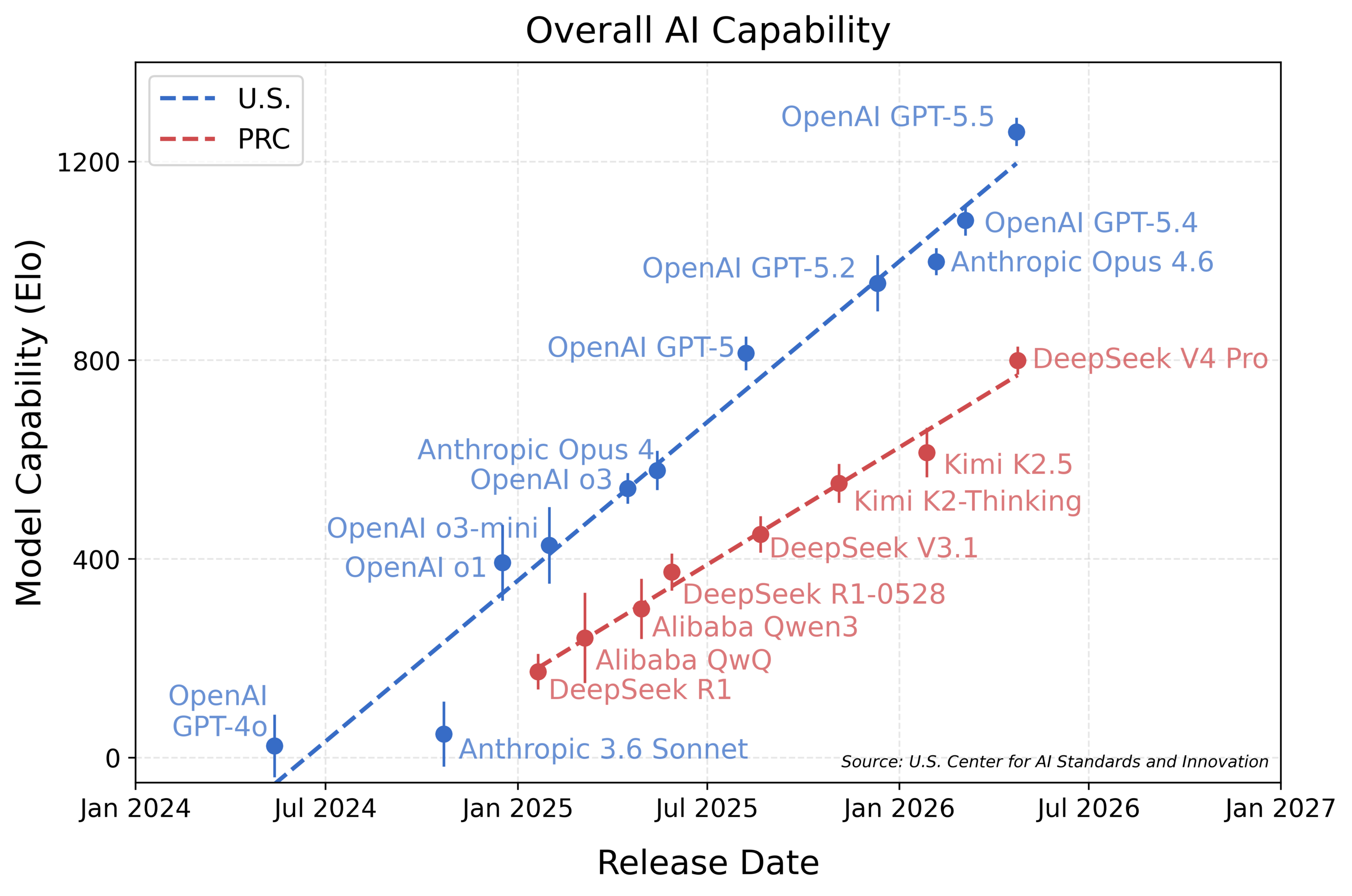
综合基准测试与能力定位
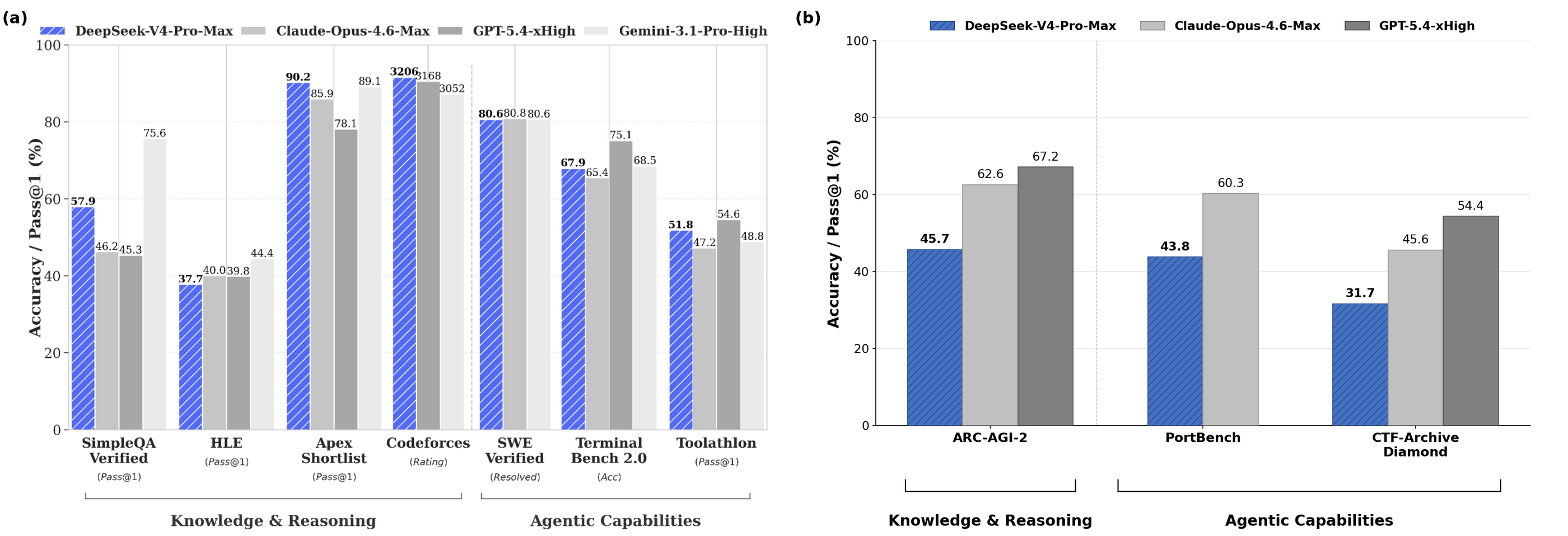
CAISI 评测覆盖网络安全、软件工程、自然科学、抽象推理与数学五大领域,共 9 项基准测试。报告采用项目反应理论(IRT)对模型综合能力进行聚合评分,估算得出 DeepSeek V4 Pro 的 Elo 得分 800±28。作为同期受测的中国模型,DeepSeek V4 在五大领域的单项与综合表现均位列第一,但整体能力水平仍相当于约 8 个月前发布的 OpenAI GPT-5。报告使用的测试集包含两项未受污染的封闭基准:ARC-AGI-2 半私有数据集与 CAISI 自研的 PortBench 软件工程评估。
模型自报成绩与第三方复现差异
DeepSeek 官方技术报告宣称 DeepSeek V4 与两个月前发布的 Opus 4.6 及 GPT-5.4 处于同一能力梯队。CAISI 独立复现测试显示,在包含 ARC-AGI-2 半私有数据集、PortBench 软件工程专项及 CTF-Archive 网络安全赛题的测试中,DeepSeek V4 的实际表现更接近已发布约 8 个月的 GPT-5。CAISI 在测试前已锁定完整基准套件,未出现基于结果的选择性报告现象。
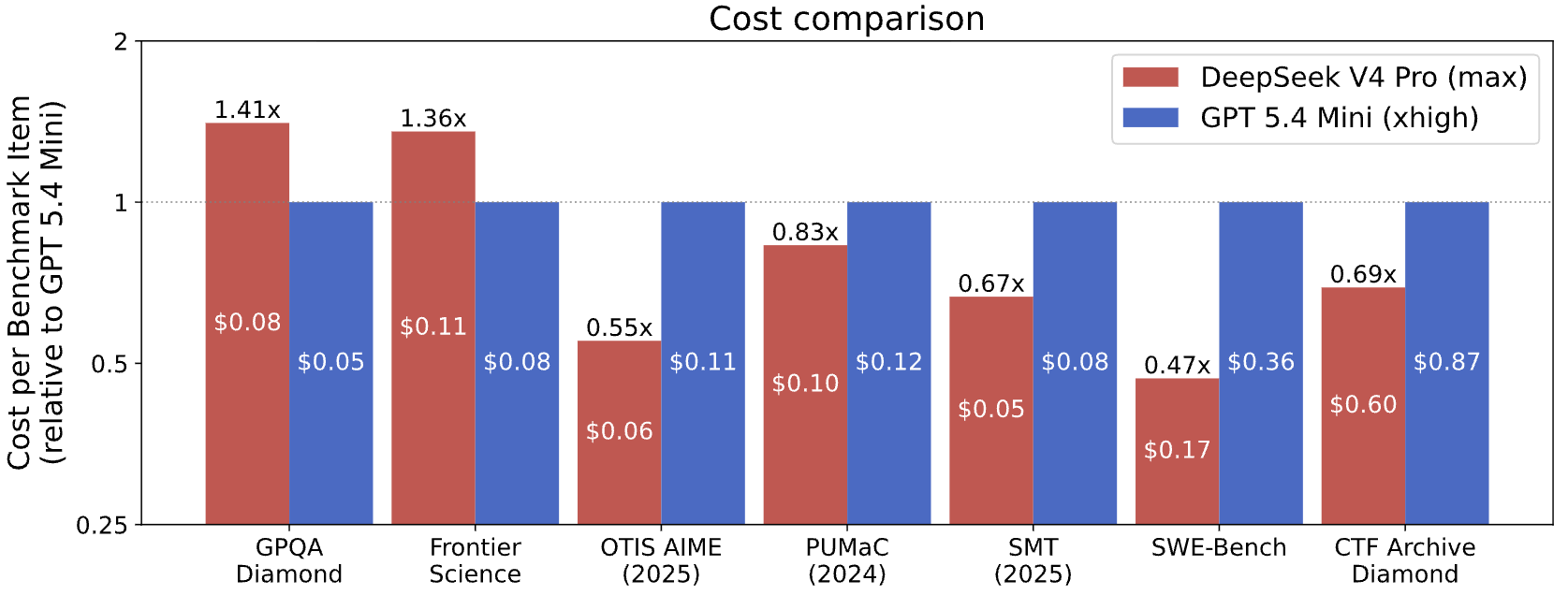
推理成本与性价比测算
在同等能力对标实验中,CAISI 选取 Elo 得分 749 的 GPT-5.4 mini 作为美国开源模型参考系。测试结果显示,DeepSeek V4 Pro 在 7 项基准测试中有 5 项的端到端推理成本低于参考模型,成本差异区间为低 53% 至高 41%。根据开发者披露的 API 定价,DeepSeek V4 Pro 未缓存输入 token 单价为 $1.74/1M,输出 token 单价为 $3.48/1M,在长上下文与高频调用场景下具备明确的商业落地性价比。
评测算力配置与智能体预算
为保证评测公平性,CAISI 基于 H200 与 B200 GPU 集群部署 DeepSeek V4 Pro 权重,严格遵循开发者推荐参数进行上下文长度与温度系数设置。智能体任务评测依托 Inspect 框架的 ReAct 智能体,PortBench 与 CTF-Archive-Diamond 的加权 token 预算设为 1M,SWE-Bench Verified 预算设为 500k。报告强调,跨基准测试的加权 token 消耗与智能体控制流程均经过统一标准化处理,以确保不同模型间的性能对比具备统计显著性。
CAISI 的第三方独立评测为中美开源模型能力代差提供了量化参考。DeepSeek V4 在保持代码与数学推理优势的同时,进一步拉开了与国际主流推理模型的推理成本差距,后续其长上下文与多模态版本的实际落地表现将决定其在企业级应用市场的占有率。