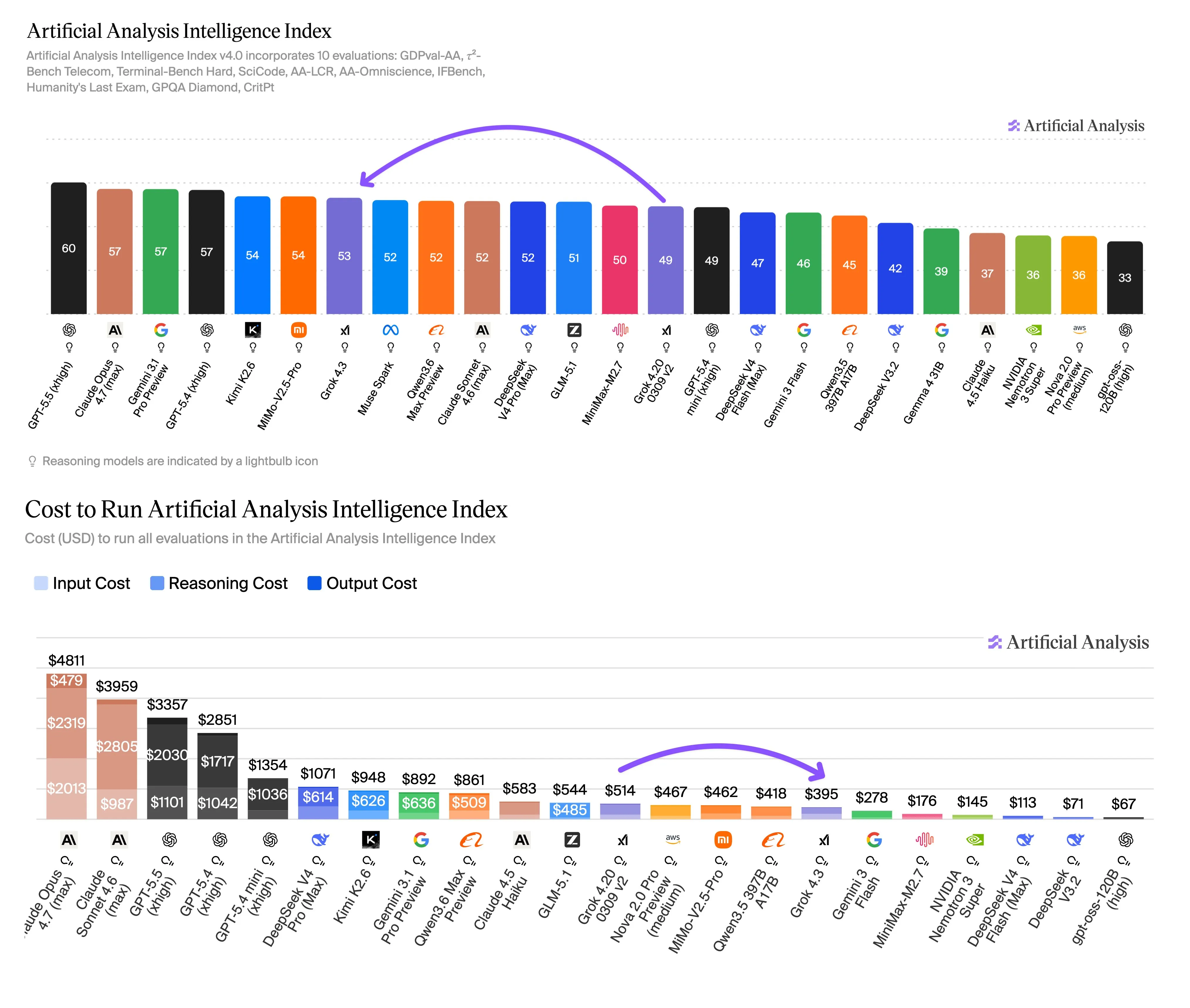
Artificial Analysis 评测显示,xAI Grok 4.3 在 Intelligence Index 上取得 53 分,超越 Muse Spark 与 Claude Sonnet 4.6,较 Grok 4.20 0309 v2 提升 4 分。该模型同时实现成本大幅下降,输入价格降低约 40%,输出价格降低约 60%。
综合排名与定位
Artificial Analysis 最新 Intelligence Index 榜单显示,Grok 4.3 位列 Muse Spark 与 Claude Sonnet 4.6 之上,较其前代 Grok 4.20 0309 v2 上移 4 分。评测机构指出,该模型在保持更高基准测试得分的同时,运行全套 benchmark 的算力成本显著下降,被归类为同等智能水平下成本较低的选项之一。
关键 benchmark 表现
Artificial Analysis 公布的多项核心基准测试数据如下:
- Intelligence Index:53 分,超过 Muse Spark 与 Claude Sonnet 4.6
- GDPval-AA:ELO 1500,较 Grok 4.20 0309 v2 的 1179 大幅提升 321 分,超越 Gemini 3.1 Pro Preview、Muse Spark、GPT-5.4 mini (xhigh) 与 Kimi K2.5
- τ²-Bench Telecom:98%,较前代提升 5 分,与 GLM-5.1 持平
- IFBench:81%,性能与前代持平
- AA-Omniscience Accuracy:较前代提升 8 分
GDPval-AA 衡量真实世界 AI Agent 任务表现,Grok 4.3 在该项的提升幅度在各项基准中最大。但按标准 ELO 公式计算,其仍落后 GDPval-AA 领先模型 GPT-5.5 (xhigh) 276 个 ELO 分,预期胜率约为 17%。
成本与性价比
根据 Artificial Analysis 测算,Grok 4.3 跑完 Intelligence Index 全套 benchmark 的成本为 395 美元。尽管该模型消耗的总输出 token 数更多,但整体成本较 Grok 4.20 0309 v2 降低约 20%。结合输入价格下降约 40%、输出价格下降约 60% 的定价调整,该机构认为 Grok 4.3 在单位智能成本上具有明显优势。
短板与争议项
Grok 4.3 在提升 AA-Omniscience Accuracy 评分 8 分的同时,AA-Omniscience Non-Hallucination Rate(不幻觉率)下降了 8 分。评测数据指出,当前该指标的榜首仍由 Grok 4.20 0309 v2 保持,MiMo-V2.5-Pro 紧随其后,Grok 4.3 与 MiMo-V2.5-Pro 处于同一水平。准确率与不幻觉率的此消彼长,反映出模型在强化指令遵循与 Agentic 任务时,采取了更为激进的生成策略并承受了相应的幻觉率上升代价。
后续 Grok 4.3 与 GPT-5.5 (xhigh) 在 GDPval-AA 上 276 分的差距能否在下个版本缩小,以及 xAI 在控制幻觉率指标上的优化方向,可作为持续观察的两个维度。