阿里 Qwen 团队开源可解释性工具 Qwen-Scope,基于 Qwen3 与 Qwen3.5 系列共 7 个模型训练所得,提供 14 组稀疏自编码器(SAE)权重。该工具通过在隐藏层插入 SAE 并施加稀疏性约束,提取高度解耦的可解释性特征,覆盖稠密模型与混合专家模型两类架构。
覆盖范围与训练规模
官方技术报告显示,Qwen-Scope 训练采样自对应模型预训练数据的 0.5B 词元规模,以确保特征分布广泛、语义稳定。开源权重涵盖 Qwen3-1.7B-Base、Qwen3-8B-Base、Qwen3-30B-A3B-Base、Qwen3.5-2B-Base、Qwen3.5-9B-Base、Qwen3.5-27B 指令模型与 Qwen3.5-35B-A3B-Base 共 7 个底座,SAE 特征数从 32K 到 128K 不等,扩展倍数为 16 倍或 64 倍。
推理结果定向控制
通过控制特征激活,Qwen-Scope 可实现对推理结果的定向修改,涵盖语言、实体、风格等维度,无需显式给出自然语言指令。该能力可用于内容风格统一、跨语言输出控制等场景。
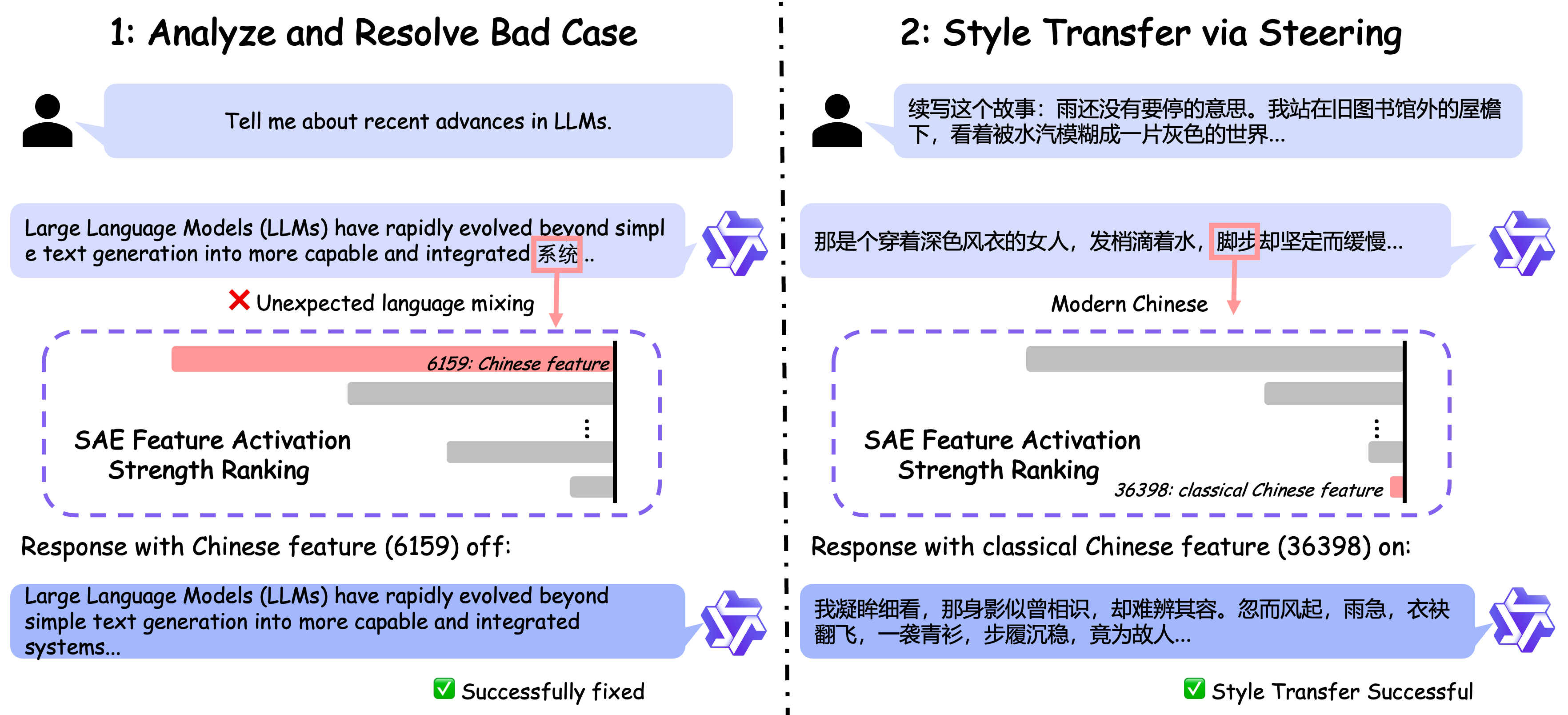
数据分类与长尾合成
在毒性数据分类场景中,基于少量种子数据即可分析毒性样本的 SAE 激活模式,筛选高相关特征用于分类,无需额外训练分类器。在数据合成层面,可识别已有数据中激活次数少甚至未激活的特征,定向补充长尾样本,官方数据显示训练数据能效比可提升至约 15 倍。
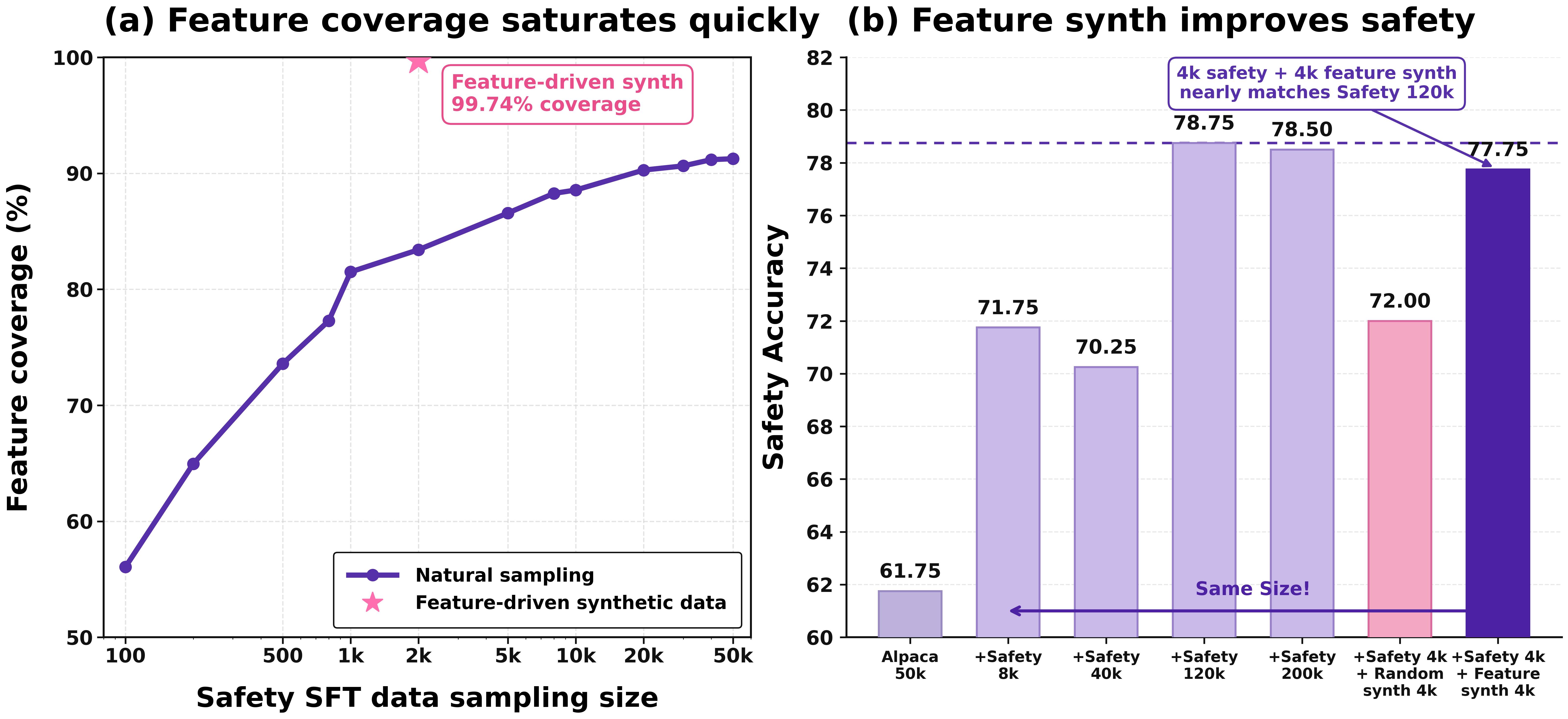
训练阶段的定向调优
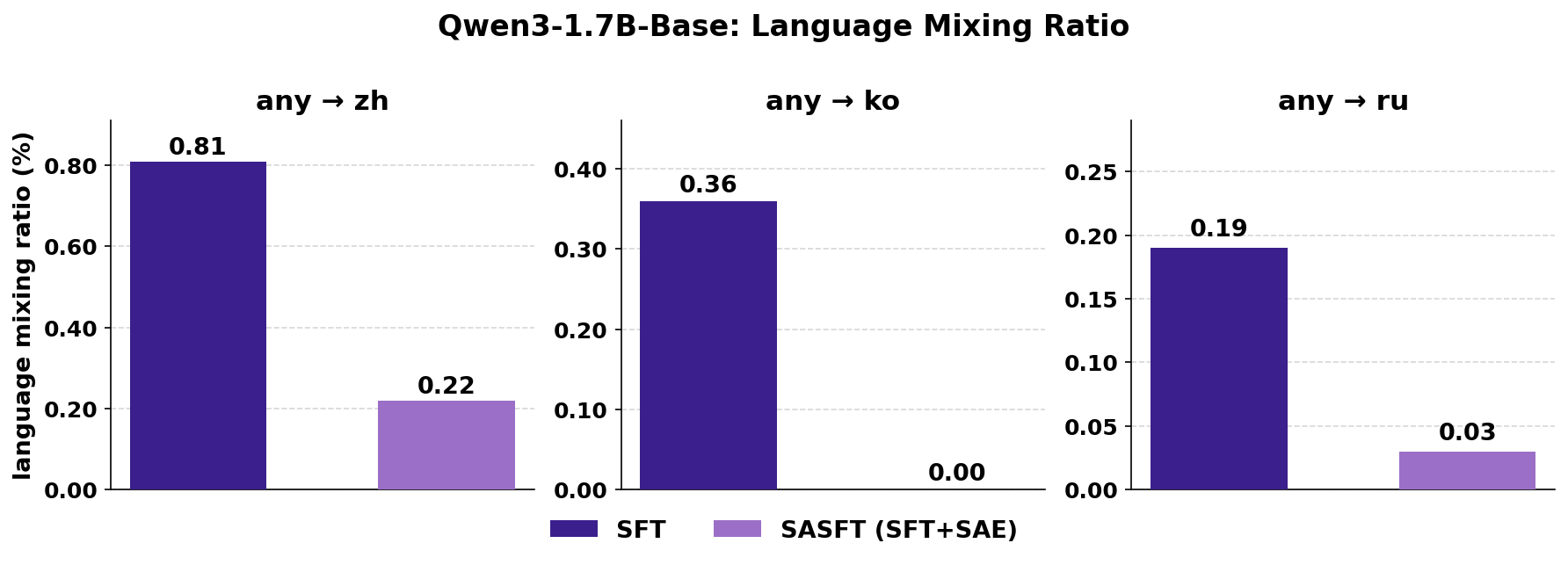
Qwen-Scope 可定位语言混用、重复生成等低频错误对应的异常激活特征。在监督微调阶段,可针对异常特征设计损失函数降低 badcase 频率;在强化学习阶段,可通过控制特征提高异常采样频率,增加学习奖励密度。
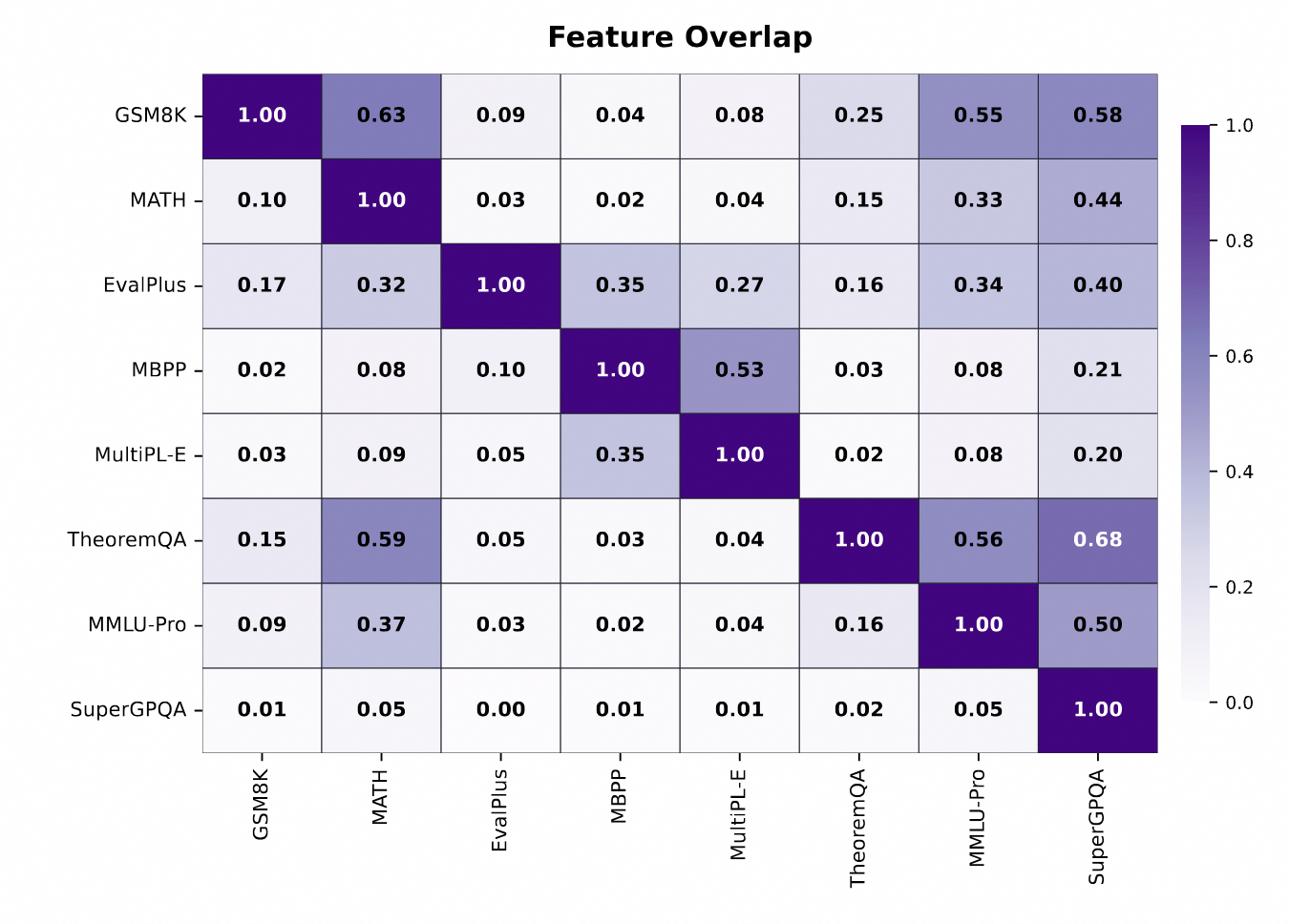
评估冗余度分析
通过对比不同评测集间的特征激活模式,Qwen-Scope 可量化评测集之间的冗余程度。Qwen 团队指出,部分常用评测集在激活特征上存在互相覆盖,导致重复评估,该工具可辅助挑选覆盖度更高、成本更低的测试样本。
Qwen-Scope 权重已上线 Hugging Face 与 ModelScope(魔搭)。可解释性工具与底座模型同步开源的做法,在国内大模型团队中较为少见,后续在第三方研究中的实际应用值得关注。